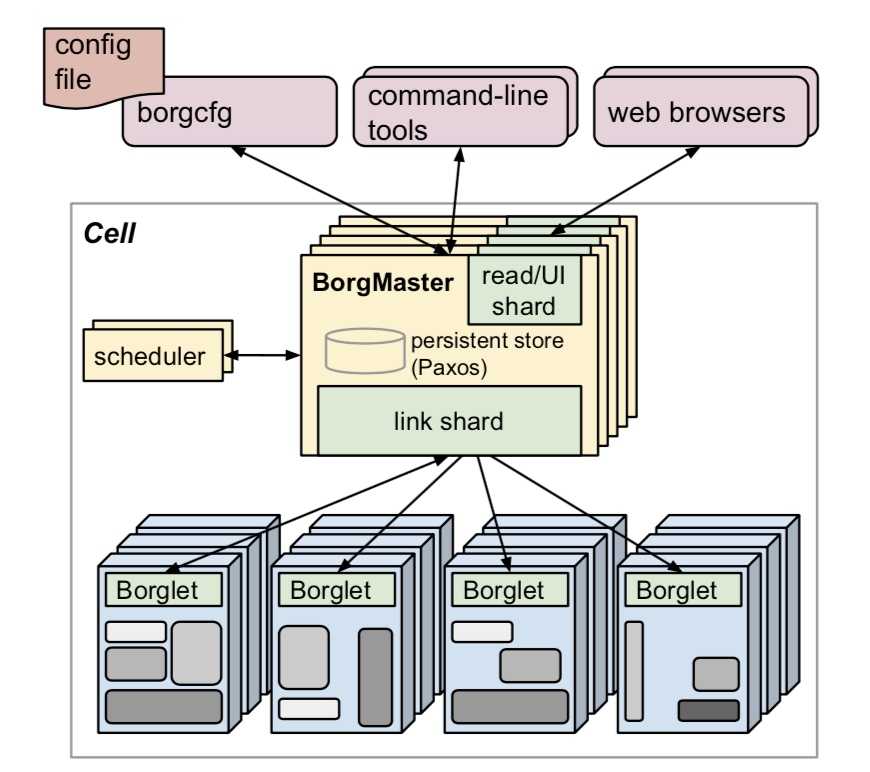
BorgMaster在全局进行任务调度和分配资源,Borglet管理主机层面的资源隔离。
相关笔记:谷歌Borg论文阅读笔记(一)—— 集群操作系统
Google的混部情况
Google几乎所有的机器都是混部的,在一台机器上,可能运行着不同jobs的tasks。根据论文中所说,Google的50%的机器运行了9个甚至更多的tasks。90%的机器运行着25个tasks,达到4500个线程。
因此,Google有完善的隔离技术来保证task之间不相互影响。目前,Google使用的隔离技术是Chroot和Cgroup。Cgroup是Google最先提交到内核社区的。
对于外部的软件,比如GAE和GCE,Google的做法是让它们运行在虚拟机(KVM)上,KVM进程被作为Borg的task运行。也就是说,KVM运行在Borg之上。
资源共享的问题
资源共享带来的问题主要就是两个,一个是安全,一个是资源之间的性能影响。
安全隔离
系统采用了Chroot隔离了文件系统。对于程序的调试,全都通过Borg来操作,Borg会让用户的命令在和被操作的tasks同一个容器下的shell中运行。
性能影响
对于性能的影响,Google使用了很多技术来减少影响,这个是文章后面详细讲的。这里主要讲的是Google对任务混部对CPU性能影响的研究。
Google为了评估不同任务部署到同一个机器的CPU干扰影响做了一个实验。他们使用CPI(每条计算机指令执行所需的时钟周期)来衡量性能干扰。当CPI增加一倍,CPU密集型程序运行时间就会增加一倍,对应于即时相应的程序,可能就是延时增加了一倍。
实验发现,CPI和2个相同时间间隔的测量成正相关: 机器的整体CPU使用率,以及运行在机器上的tasks。
- 添加一个task到一台机器上,会增加别的任务0.3%的CPI(使用线性模拟合数据)。
- 增加10%的CPU利用率会增加2%的CPI。
这是CPU密集型的程序测量的结果,事实上干扰存在于各种资源。
相对而言,专用的cells的CPI要低于混用的cells。据Google的统计,共享cells的CPI平均值为1.58(σ = 0.35)。在专用cells中,CPI平均值为1.53(σ = 0.32),CPU性能在共享cells中有大约下降3%。
但这也表明,使用共享的cells并没有大幅度增加程序运行的成本,而在机器需求方面,共享的cells更节约机器。另外。共享的优势适用于所有资源,包括内存和磁盘,而不仅仅是CPU。当然,Google还是有些特别的服务是放在专用的cell上的。
Google也对cell的大小进行了评估,发现cell越大越节约机器。
任务分类
Google对jobs是分类为prod和non-prod的。prod指的是面向应用这类jobs,non-prod指的是批处理这类jobs。对于主机上的tasks,则是分为延迟敏感型(latency-sensitive)和 批处理(rest)。因为non-prod的jobs中的master应该也是延迟敏感的,所以需要在task上进行分类。
个人理解: non-prod和prod是在BorgMaster调度时看的,是一个全局的维度。而latency-sensitive和rest是Borglet在主机的task层面上看的,是一个进程的维度。
另外,Borg中,主机的资源其实是超卖的(不然怎么节约资源),包括可压缩和不可压缩的资源。因此,可能会出现所有tasks都没有超过限制值,而主机资源不足的情况。此时,就需要根据task的分类来进行取舍。
延迟敏感型(latency-sensitive)
未作特殊说明,下面采用缩写LS tasks来表示延迟敏感型的任务。
LS tasks用于面向用户的应用,以及共享设施服务,它需要快速响应请求。高优先的LS tasks享受最好的待遇。能暂时让批处理饥饿几秒钟。
批处理(rest)
用于离线计算的进程,用于利用那些再生资源。基本是说被kill就被kill。
资源分类
混部的一大问题是某个资源不足的情形。但是,不同的资源有不同的特点,有的资源能快速调整,而有的则需要很大的代价来调整。因此,Borg将资源分为两大类:可压缩资源(compressible resources)和不可压缩资源(non-compressible resources)。
可压缩资源(compressible resources)
这种资源指的是CPU,磁盘IO这类资源。它们是基于比例的,可以通过降低服务质量来调整资源分配,这种调整消耗的代价极少,几乎可以忽略。
可用的方案
- CPU:Cgroup中的cpu子系统,可以限流CPU执行周期,也可以调整调度权重。
- IO:Cgroup中的disk子系统,可以在块设备层面限流IOPS和流量。也能在更底层的IO调度层调整权重(权重调整只支持CFQ,但是注意CFQ并不适合SSD)。
对LS tasks的优待: LS tasks可以保留完整的CPU核心,阻止其它LS tasks使用它们。批处理tasks可以运行在任何CPU核心下,但它被给予相对于LS tasks很小的调度份额。Borglet动态调整LS tasks的资源限制,为了确保它不会把批处理tasks饿死几分钟,在需要的时候,选择性的应用CFS控制带宽。
CFS改进: Cgroup中,CPU子系统是依赖于CFS调度算法,这是目前Linux的默认任务调度算法。Google为了减少调度延时和高利用率,调优了CFS调度程序。另外,Google的程序多采用多线程模型,这能减轻持续负载失衡的影响。
- 允许
LS tasks抢占批处理的tasks。 - 多个
LS tasks在一个CPU下运行时,减少调度量。
主机资源超配: 如果机器用尽了可压缩资源,Borglet会对某些task进行限流处理(给对LS tasks足够的资源)。这样,短负载峰值就可以被处理,而不需要kill掉任何tasks。如果情况没有改善,Borgmaster会从这台机器上迁移掉一些tasks。
不可压缩资源(non-compressible resources)
这种资源的典型代表是内存和磁盘容量。
此类资源的调整是很难的,比如内存。在内存不足的时候,Linux会进行内存回收,释放PageCache,将部匿名页调入Swap。 如果还是没有足够的内存,会进入OOM-KILL流程。这个代价是很大的。
因此,如果不可压缩资源不足,就只能kill掉进程来回收资源,这也是操作系统的逻辑。
可用的方案
- 内存: Cgroup的memory子系统可以支持限制内存使用。Cgroup内的内存有自己的LRU链,所以Cgroup内部也会自动换页。此外,在Cgroup内的内存用尽之时,也会触发Cgroup内的
OOM-KILL流程。另外,系统自身的OOM-KILL级别是高于Cgroup的。 - 磁盘: 这块不清楚Google是怎么做的,Cgroup也没有支持这个。有的软件是quota磁盘限额,可以限定文件夹内使用磁盘空间的大小,超过了就禁止写入。最早听说这是间隔扫描的方式,觉得不靠谱,现在应该改进成用inotify了。
主机资源超配: 当不可压缩资源不足时,Borglet会从优先级最低的task开始kill,直到资源足够。
资源分配:
细粒度资源请求:
Google的资源分配是由用户申请的,用户可以指定各种资源的所需大小。而不是类似售卖虚拟那样有固定的规格。
Google对此做过实验,使用固定规格容器,根据CPU核心和内存两个维度的限制,四舍五入到下一个大于等于资源需求的规格。最小规格为0.5个CPU核心,1G内存。实验的结论是,这么做会增加30%-50%的资源开销。而且这还是在cell被压实之前的,压实后cell的资源开销更低。此外,cell还能支持CPU和内存的独立伸缩。
资源分配方法
每个tasks和资源有3个相关的数据。分别是:申请值,估值,使用值。
1. 申请值:也就是限制值,申请资源时,用户填写的值。
2. 估值:Borg对程序使用资源量的估计,也被称为预定(reservation)。一般是使用值加上一定保护缓冲区。
3. 使用值:当前task使用的资源值,是采集的数据。
估值是为了能回收利用那些没被用到的资源。每过几秒,BorgMaster会进行一次计算。
最初的估值会等于申请值,300秒之后,允许启动瞬变(startup transients),它会缓慢的向实际使用加上安全边缘靠拢。如果使用量超过了估值,估值会迅速增加。
Borg调度者使用申请值(限制值)来计划prod tasks(分配时按照限制来算),因此它们从不依靠再生资源,也不会超额分配资源。对于non-prod tasks,它使用现有tasks的预定,所以新的任务能调度到再生资源(分配时按照现有估值来算)。
资源超限制值:
Tasks允许使用资源量通常在限制值内。但只要主机资源足够,就可以使用超出限制值的资源。当然,这会增加tasks被Kill掉的可能性。当BorgMaster分配任务时发现资源不足时,它会优先回收超过限制值的tasks的资源。
大多数tasks允许使用可压缩资源超过限制值。比如CPU,Borg以此来利用未被利用的(松弛)资源。在Google中,只有5%的LS task禁止使用资源超过限制值,大概是为了获得更好的可预测性。只有少于1%的批处理tasks这么做(禁止资源使用超过限制值)。
使用内存超过限制值默认是被禁止的,因为这增加了task被kill掉的机会。但即使如此,10%的LS tasks重写了这个(允许内存使用超过限制值)。79%的批处理任务这么做,因为这是MapReduce框架的默认设置。
总结
- 应用混部,尽可能使用多线程。
- 使用轻量级的隔离机制,而不是VM。
- 合理的对资源超分配,以此提高资源利用率。很多任务并不是任何时刻都会用到很多资源。
- 对任务和资源进行分级。总体上,以高优先的
LS task为核心,批处理任务以一个填坑的角色来吃掉剩余的资源。尽可能不kill任务,万不得已情况下先拿低优先级开刀。



暂无评论内容